[논문리뷰]MSTA3D: Multi-scale Twin-attention for 3D Instance Segmentation
Paper Overview
ACM MM'24
https://arxiv.org/abs/2411.01781
MSTA3D: Multi-scale Twin-attention for 3D Instance Segmentation
Recently, transformer-based techniques incorporating superpoints have become prevalent in 3D instance segmentation. However, they often encounter an over-segmentation problem, especially noticeable with large objects. Additionally, unreliable mask predicti
arxiv.org
Abstract
본 논문은 point cloud instance segmentation 논문이다.
superpoint를 사용한 transformer 기반 방법들은 over-segmentation 문제를 가지고 있다.
또, superpoint mask 예측으로부터 신뢰도가 낮은 mask prediction이 이 문제를 더욱 심화시킨다.

따라서 본 논문은 이를 해결하기위한 MSTA3D framework를 제안한다.
먼저 multi-scale superpoint feature representation을 이용하고 이를 인식하기 위해 twin-attention mechanism을 도입한다.
또, MSTA3D는 box query와 box regularizer를 통합하여 semantic query와 함께 상호 보완적인 공간 제약을 제공한다.
Keywords
Point Cloud Instance Segmentation, Superpoint-based Segmentation
Related Work
참조한 선행 연구
Superpoint Transformer for 3D Scene Instance Segmentation [paper]
Mask3D: Mask Transformer for 3D Semantic Instance Segmentation [paper]
Mask-Attention-Free Transformer for 3D Instance Segmentation [paper]
Query Refinement Transformer for 3D Instance Segmentation [paper]
Superpoint generation
Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs [paper]
Box Guided twin-attention decoder for multi-scale superpoint
1. Architecture Overview
3D instance segmentation의 목표는 $N_{I}$개의 독립적인 object instance의 point-wise 경계를 예측하는 것이다.
superpoint based 방법은 먼저 point clouds로부터 $N_{h}$개의 superpoint가 만들어진다.
따라서 $\mathbf{M} \in \left\{ 0,1 \right\}^{N_{I} \times N_{h}}$ binary mask를 얻는 것이다.
또 instance mask에 대응하는 $N_{C}$개의 semantic label도 예측해야 한다. $\mathbf{C} \in \mathbb{Z}^{N_{I} \times N_{C}}$
이를 위해 저자들은 다음과 같은 framework를 제안한다.

이 framework는 크게 backbone network, twin-attension decoder, box regularizer로 구성된다.
2. Backbone Network
backbone network는 3D U-Net을 사용하며 SPFormer 방법과 동일하다.
또 superpoint를 사용하여 memory cost를 줄였다.
그러나 superpoint 방식은 over-sclustering을 유발할 잠재적인 가능성이 있다.
따라서 저자들은 이 superpoint를 multi-scale로 생성하여 사용한다.
따라서 backbone network로부터 추출된 feature를 각 superpoint에 pooling하여 사용한다.
3. Twin-attention Decoder
Region Constraint Instance Query
저자들은 instance mask의 영역을 guide하기 위해 semantic query에 추가로 덧붙이는 box query를 제안한다.
이 guidence는 model이 Region of Interest에 더 집중할 수 있게 만들어준다.
결론적으로, 랜덤으로 초기화된 learnable instance queries $\mathbf{X}^{0} \in \mathbb{R}^{N_{o} \times D_{o}}$를 사용한다.
이때 $\mathbf{X}^{0} = [X_{s};X_{b}]$이며 $\mathbf{X}_{s} \in \mathbb{R}^{N_{o} \times D_{s}}$이고 $\mathbf{X}_{b} \in \mathbb{R}^{N_{o} \times 6}$다.
이때 $N_{o}$는 $N_{I}$보다 크고 proposal은 높은 confidence가 선택된다.
Twin-Attention-Based Feature Extraction
twin-attention-based decoder 구조는 다음과 같다.

이것은 6개의 twin-attention block의 stack으로 구성되어 있다.
각 block은 cross and self-attention module, feature fusion module, instance prediction module로 구성되어 있다.
$\pi_{c}(\cdot)$은 attention module의 linear projection 모듈로 Q,K,V matrix를 출력한다.
$\mathbf{Q}^{L} = \pi_{q}^{L}(\mathbf{X}^{L-1}) \in \mathbb{R}^{N_{o} \times D_{o}}$
$\mathbf{K}_{l}^{L} = \pi_{k}^{L}(\mathbf{S}_{l}) \in \mathbb{R}^{N_{l} \times D_{o}}$
$\mathbf{V}_{l}^{L} = \pi_{v}^{L}(\mathbf{S}_{l}) \in \mathbb{R}^{N_{l} \times D_{o}}$
$\mathbf{K}_{h}^{L} = \pi_{k}^{L}(\mathbf{S}_{h}) \in \mathbb{R}^{N_{h} \times D_{o}}$
$\mathbf{V}_{h}^{L} = \pi_{v}^{L}(\mathbf{S}_{h}) \in \mathbb{R}^{N_{h} \times D_{o}}$
이제 다음과 같이 twin attention(TATT)가 계산된다.

high-scale attention에 대해서, superpoint mask attention $A_{h}^{L-1} \in \mathbb{R}^{N_{o} \times N_{h}}$을 사용한다.
이때 임계값 $\tau = 0.5$다.
이 cross-attention 출력값은 residual connetion과 layer norm을 거쳐 $\mathbf{Y}_{l}^{L} \in \mathbb{R}^{N_{o} \times D_{o}}$와 $\mathbf{Y}_{h}^{L} \in \mathbb{R}^{N_{o} \times D_{o}}$를 얻는다.
이를 사용해서 mask 없이 식(1a)와 식(1b)와 같이 self-attention을 계산하고 출력 $\mathbf{Z}_{l}^{L} \in \mathbb{R}^{N_{o} \times D_{o}}$, $\mathbf{Z}_{h}^{L} \in \mathbb{R}^{N_{o} \times D_{o}}$를 얻는다.
이 두 multi-scale 출력을 합치기 위해 element-wise 곱을 한 후 feedforward layer에 입력하여 $\mathbf{X}^{L} \in \mathbb{R}^{N_{o} \times D_{o}}$을 얻는다.

이것은 다음 twin-attention block과 box regularizer의 입력으로 사용된다.
학습 때는, twin-attention block이 SPFormer와 같이 iterative predction strategy를 사용하여 순차적으로 학습한다.
inference 때는, 마지막 decoder block의 출력 ($\mathbf{X}^{6}$)이 최종 instance proposal을 제공한다.
Instance and Box Prediction
instance prediction module은 $\mathbf{X^{L}}$을 입력으로 받아 MLP를 통해 각 instance의 mask score $\widetilde{\mathbf{M}}_{s} \in \mathbb{R}^{N_{o}}$와 대응되는 class $\widetilde{\mathbf{C}} \in \mathbb{R}^{N_{o} \times N_{C}}$를 계산한다.
추가로, 잠재 instance 쿼리들의 정보를 충분히 이용하기 위해, instance box predction $\widetilde{\mathbf{B}} \in \mathbb{R}^{N_{o} \times 6}$과 box score $\widetilde{\mathbf{B}}_{s} \in \mathbb{R}^{N_{o}}$를 구한다.
이 box label은 instance label로 부터 계산한다. $[x_{min}, y_{min}, z_{min}, x_{max}, y_{max}, z_{max}]^{T}$
이것을 통해 모델은 local spatial 정보를 학습할 수 있으므로 모델 성능을 개선할 수 있었다고 한다.
4. Spatial Constraint Regularizer

이 regularization은 spatial latent fature의 representation을 향상하는 것을 목표로 한다.
이때 regularizer는 $\widetilde{\mathbf{B}}$와 $\mathbf{S}_{h}$를 MLP에 입력하여 출력한 scene-wise semantic score $\mathbf{F}_{m} \in \mathbb{R}^{N_{h} \times D_{s}}$, scene-wise box information $\mathbf{F}_{b} \in \mathbb{R}^{N_{h} \times 6}$을 입력으로 받는다.
이제 다음과 같이 relative positional difference $\mathbf{R}_{i} \in \mathbb{R}^{N_{h} \times 6}$를 계산한다.

이 $i$는 instance proposal $N_{o}$중 하나를 의미한다.
따라서 $\widetilde{\mathbf{b}}_{i} \in \mathbb{R}^{6}$는 $\widetilde{\mathbf{B}}$의 한 요소를 나타내며, $\mathbf{F}_{b}$와 연산을 하기 위해 broadcating을 적용한다.
각 twin-attention block의 binary mask를 예측하기 위해 다음과 같이 계산한다.

위 식을 보면 $\mathbf{R}$과 $\mathbf{F}$에 concat operation이 적용된 것을 볼 수 있다.
따라서 concat feature의 최종 차원은 $\mathbb{R}^{N_{0} \times (N_{h} \times (6 + D_{s}))} = \mathbb{R}^{N_{o}\ \times (N_{h} \times D_{o})}$다.
$\odot$은 batch matrix multiplication으로 $\mathbf{X}^{L}$을 broadcating을 하여 계산한다.
$Linear$는 차원을 늘리지 않는다.
5. Training and Inference
Training
이 모델을 학습하기 위해 다음과 같은 loss를 사용한다.

mask를 위해서 binary cross-entropy loss $\mathcal{L}_{bce}$와 dice loss $\mathcal{L}_{dice}$를 사용한다.
classification을 위해서는 cross-entropy loss $\mathcal{L}_{cls}를 사용한다.
추가적인 loss는 다음과 같다.

proposal을 ground-truth instance에 매칭하는 방법과 inference는 SPFormer와 같다.
Experiments
1. Dataset and Evaluation Metric
ScanNetV2, ScanNet200, S3DIS를 사용한다.
mAP를 사용한다. (mAP 설명)
2. Implementation Details

3. Experimental Results
ScanNetV2


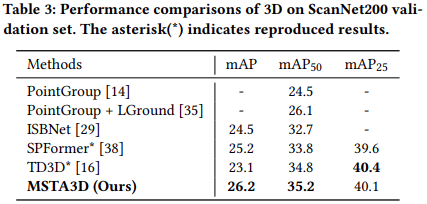
ScanNet200
S3DIS

4. Ablation Study
Multi-scale Feature Representation and Loss Functions

Number of Queries

Model Complexity

Conclusion
In this paper, we presented MSTA3D, a transformer-based method designed for 3D point cloud instance segmentation. To address the challenge of over-segmentation, particularly with background or large objects in the scene, we devised a multi-scale superpoint strategy. Furthermore, we introduced a twin-attention decoder to leverage both high-scale and low-scale superpoints simultaneously. This enhancement expands the model’s capacity to capture features at various scales, thereby enabling better performance on large objects and reducing over-segmentation. In addition to the semantic query, we introduced the notion of a box query. This provides spatial context for generating high-quality instance proposals, assists the box regularizer in producing reliable instance masks, and contributes to box score regression, leading to significant performance improvements. Finally, we rigorously evaluated each of these components through extensive experiments.