이 논문은 3D segmentation을 학습시킬 때
다양한 dataset을 사용하기 위한 방법으로
prompt tuning 방법론을 제안한다.
(최근 대회를 연속 2개를 나가서 논문을 한참 못읽었다..)
arXiv'23
https://arxiv.org/abs/2308.09718
Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training
The rapid advancement of deep learning models often attributes to their ability to leverage massive training data. In contrast, such privilege has not yet fully benefited 3D deep learning, mainly due to the limited availability of large-scale 3D datasets.
arxiv.org
Abstract
3D dataset은 여러 datasets을 섞어 한 모델을
학습시키는 것이 datasets간의 domain차이로 어렵다.
단순하게 합치면 negative transfer 현상이 일어난다.
따라서 저자들은 Point Prompt Training (PPT)를 제안한다.

이것은 상조적인(synergistic) multi-dataset 학습 framework다.
이 framework로 저자들은 Prompt-driven Normalization을 제안한다.
이것은 모델을 domain-specific prompts로
서로 다른 dataset에 적응하도록 한다.
그리고 Language-guided Categorical Alignment는
label text 사이의 관계를 이용함으로써
multiple-dataset label spaces를 적절하게 통합하는 것이다.
PPT를 사용할 경우 dataset을 하나만 활용하여 학습하는 것보다
성능이 향상된다는 것을 확인할 수 있다.

2. Multi-dataset Synergistic Training
2.1 Problem Setup
Training objective
각 dataset을 $D_{i} = \left\{ ( x_{j}^{i}, y_{j}^{i}) \right\}, 1 \leq i \leq n$라고 하고
$n$은 dataset 수, $( x_{j}^{i}, y_{j}^{i})$는 data-label 쌍이라고 표현할 때
최종으로 다음 loss를 최소화 해야 한다.

$L$은 sampe-wise loss function이라 한다.
Task
저자들의 주 target은 scene-level semantic segmentation이다.
Dataset
저자들은 ScanNet, S3DIS, Structured3D를 사용한다.
Evalutation
저자들은 joint training을 통해 모든 datasets을 활용하여 학습한다.
이후 추가적인 fine-tuning과정 없이 바로 각 dataset에 테스트 한다.
또 2가지 trasfer learning setting도 고려한다.
1. supervised pre-training
2. unsupervised pre-training
2.2. Pilot Study: Uncovering the Negative Tansfer
MSC는 ScanNet과 Arikiscene datasset을 결합하여
unsupervised pre-training을 수반한다.
그러나 데이터가 3배 늘어났음에도 성능 향상은 한계가 있었다.
(ScanNet에 대해)
Negative transfer은 한 데이터셋으로 부터 학습이
다른 데이터셋에서는 부정적인 영향을 주는 현상이다.
다음 표를 보면 네이브하게 데이터셋을 합칠경우
한 데이터셋으로만 학습한것 보다 성능이 떨어지는 것을
확인할 수 있다.

3. Point Prompt Training
최근 제안된 prompt tuning은 large-scale dataset으로 pre-training된
모델을 downstream task에 효과적으로 적용하는 실행 가능한 접근법이다.
저자들은 이를 바탕으로 negative transfer을 완화시키고
multi-dataset training을 위해
Point Prompt Training (PPT)라는 패러다임을 제안한다.

PPT는 위와같이 2가지 필수 구성요소를 가진다.
(1) prompt adapter
이것은 하나의 모델이 learnable domain-specific prompts를 사용하여
다양한 데이터셋의 context를 이용하는 것이다.
(2) categorical alignment process
이것은 모델이 multiple category space 내에서 적절하게 학습되도록 한다.
3.1. Learning with Domain Prompting
Issues with prompt tuning
prompt tuning paradigm에서
large-scale dataset으로 pre-trained 모델은 prompt를 통해
추가적인 정보 또는 context를 포함함으로써 구체적인 task 또는
dataset에 fine-tuned 한다.
그러나 3D 인식의 context에서, large-scale pre-trained model의 부족은
prompt tuning의 응용을 제한한다.
나아가, prompt tuning은 pre-training이나 fine-tuning을 하는 동안
동시에 multiple datset을 학습하는 능력을 향상시키는 것보다
pre-training과 fine-tuning datset의 사이의 domain gap을
다루는데에 초점을 맞춘다.
이 문제를 해결하기 위해,
저자들은 domain prompting이라는 새로운 방법을 제안한다.
이것은 다양한 dataset context에 대한 조건으로
learnable prompt token을 포함하고
backbone과 함께 domain prompt를 (pre-)train한다.
Domain prompting
각 관심있는 dataset $D_{i}$에 대해 저자들은
$d$-dimensional vector를 domain-specific prompt로 만든다.
$n$ contexts의 모음은 $ C = \left\{ c^{i} \in \mathbb{R}^{d} | i \in \mathbb{N}, 1 \leq i \leq n \right\}$로 나타낸다.
따라서 식 (1)은 다음과 같이 수정된다.

쉽게 말하면 학습에 promt $c$가 추가된 것이라 생각하면 된다.
이 learnable domain prompts는 dataset사이의 분포 차를 발견하는데에
용이하게 하고 backone이 multi-datset training에서 마주하게될
domain gaps를 극복할 수 있게 한다.
저자들은 이 접근법이 supervised와 unsupervised의
pre-training, fine-tuning 모두에
긍정적인 영향을 줄 수 있을것이라 믿는다.
Domain prompt adapter
저자들은 prompt adapter에 대한 다양한 설계에 대해 조사한다.
main proposal에 대해서는 *표시를 한다.
Direct Injection
다양한 datasets의 domain-specific contextual cue는
이것의 respective prompt 내에서 인코딩 된다.
domain prior의 포함은 간단하게 chnnel-aligned prompt를
linear projection과 함께 중간 feature map에 더함으로써 달성된다.
Cross Attention
DETR에 영감을 받아, 저자들은 cross-attention-based
domain prompt adapter를 또하나의 방법으로 이용한다.
이 전략은 각 encoder-decoder stage의 시작점에서
skip connection과 함께 cross-attention block을 도입하는 것이다.
Prompt-driven Normalizations*

domain prompt adapter의 목적은
다양한 dataset을 가로질러 안정적이고 일반화할수 잇는
representation을 공유하도록 학습하는 것이다.
저자들은 Prompt-driven Normalization (PDNorm)의
context adapter를 도입한다.
이것은 multi-dataset training에 연관된
transfer 문제를 다루는 새로운 접근법이다.
domain prompt $c$가 주어지면,
$\gamma$와 $\beta$를 적응적으로 학습한다.

$\gamma$와 $\beta$는 각각 linear projection이다.
이 PDNorm을 backbone의 normalization layer로 교체하여 사용한다.
Zero-initialization and learning rate scaling
저자들의 prompt는 모델과 joint로 학습된다.
그러나 prompt를 랜덤으로 initialization하여 학습하면
학습이 불안정해진다는 문제가 있다.
저자들의 추측은 모델이 학습 초기에는
다양한 domain사이에서 적용할 수 있는
일반적인 지식을 습득하지만,
학습이 진행될수록 domain-specific representation을
학습하기 때문에 이런 문제가 발생한다는 것이다.
이를 해결하기 위해 저자들은
zero-initialization, learning rate scaling을 사용한다.
구체적으로 PDNorm의 $\gamma$와 $\beta$를 0으로 초기화 한다.
(파라미터가 0이면 어떻게 학습되는가에 대해 생각했는데
바이어스가 랜덤이면 괜찮을 것 같다.)
그리고 prompt-related parameter의 learning rate는
더 작게 가져가서 backbone 쵝 학습에 우선순위를 뒀다고 한다.
3.2. Categorical Alignment
추가적으로 중대한 문제가 있다.
그것은 서로다른 datasets에 대해 label space의
inconsistency를 다뤄야 하는 것이다.
(아마 dataset마다 class가 다 다른데 이걸 one-hot vector로 다루기엔
무리가 있다 판단한듯)
따라서 저자들은 여러 방법을 시도했다.
Decoupled
가장 쉬운 방법은
dataset마다 linear projection head를 불리하여 적용하는 것이다.
이 방법은 확실하게 inconsistency를 다룰 수 있으나,
파라미터가 너무 많아지고,
dataset class간의 잠재적인 연관성을
설명하는데에 실패하게 된다.
Unionized
다른 직관적인 방법은
shared linear segmentation head를 구성하여
representation space를 통일된 label space로 project하는 것이다.
단 loss 계산은 분리된 채로 남아있고
dataset의 label space는 구별되도록 강제된다.
Language-guided*
저자들은 language-guided categorical alignment를 제안한다.
이것은 각 point representation을
category-language embedding으로 하는 것이다.
(CLIP text encoder 사용)
4. Experiments
4.1 Ablation Study
저자들은 SparseUNet을 사용한다.
Prompt adapter

위 표는 앞서 언급한 prompt adapter 방법에 대한 비교다.
add는 direct injection이라는 뜻이다.
저자들의 PDNorm의 성능이 가장 좋다.
Zero-initialization and learning rate scaling

저자들은 zero-initalization을 사용하고
prompt 에 대한 learning rate를 0.1로 주어
성능을 향상시켰다.
Prompt location

저자들은 prompt의 위치에 따른 실험을 진행했다.
Prompt length

저자들은 domain prompt의 차원에 대해 연구했다.
그중 256차원이 가장 성능이 좋았다.
Categorical alignment
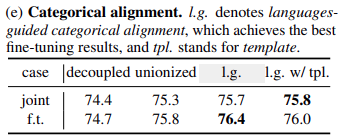
저자들은 저자들은 languages-guided categorical alingment
방법이 가장 좋았고
간단하게 "A point of [class]"라는 prompt로도 시도해봤다고 한다.
Language-guidance criteria

loss는 InfoNCE가 가장 좋았다고 한다.
Sampling ratio

저자들은 dataset간의 sampling 비율을 찾았는데
Struct.3D:ScanNet:S3DIS = 4:2:1이 가장 좋았다고 한다.
Joint training data

4.2. Results Comparision
Indoor semantic segmentation results

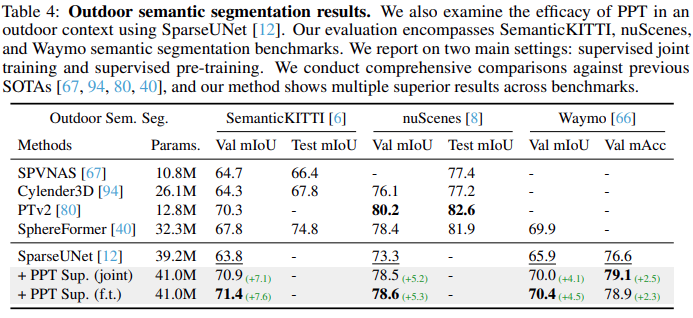
Outdoor semantic segmentation results
Indoor instance segmentation results

Data efficient benchmark

6. Conclusion and Discussion
저자들은 효과적으로 3D multi-dataset을 시너지있게
학습하는 방법론을 제안한다.
특히 negative transfer을 극복하기위해
Prompt-driven Normalization과
Language-guided Categorical Alignment를 제안한다.
논의
Module design
저자들은 아직 모델 구조가 최적화 되지 않았다고 생각한다.
Data domain
이 연구는 향후 합성데이터+실제 데이터까지 확장되고
또 실내+실외 데이터까지 확장될 수 있을것이라고 한다.
Multi-task training
향후 multi-task 모델까지 기대하고 있다.
Model capacity
저자들의 방법은 더이상 한 데이터셋에
overfitting을 보이지는 않지만 반대로 underfititing이 일어난다고 한다.
Appendix
A Alternative Designs
A.1. Domain Prompt Adapter Zero-initialization

저자들은 zero-initialized layer에는 초록생 박스를 쳤다.
Direct Injection
해당 방법은 직접적으로 adapter를 block 시작부분에 넣는다.
Cross Attention
해당 방법은 Direct Injection의 확장 버전으로
prompt를 통해 attiontion을 진행한다.
Prompt-driven Normalization
이것은 각 normalization layer를
PDNorm으로 변경하는 것이다.
A.2. Categorical Alignment

Decoupled
분리된 prediction head는 각 dataset마다 존재한다.
shared backbone이 point embedding을 추출한 다음
구체적으로 댕응되는 dataset domain의 head에 입력하는 것이다.
loss계산은 각 head에서 따로 수행된다.
Unionzied
point embedding은 domain마다 분리하지 않고 사용한다.
대신에 이것들은 unified prediction head를 통과하고
이 space에서 logit이 예측된다.
그러나 여전히 loss를 계산할때는
domain category space에 대응되는 prediction space로
분리해야하는 제한이 있다.
Language-guided
이 방법은 CLIP text encoder를 이용하여 category를
text embedding으로 변환한다.
이후 InfoNCE loss를 사용하여 학습을 하고
최종 예측은 embedding의 similarity를 통해 예측한다.
B. Additional Experiments
B.1. Experimental Settings




B.2. Additional Pilot Study: Naive Joint-training with Varied Sampling Ratios

B.3. Additional Results


B.4. Additional Ablation Study


'3D point clouds > Segmentation' 카테고리의 다른 글
| [논문리뷰]PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation (0) | 2025.03.19 |
|---|---|
| [논문리뷰]3D Compositional Zero-shot Learning with DeCompositional Consensus (0) | 2023.11.21 |
| Point Transformer 리뷰 (0) | 2023.08.09 |
| [논문리뷰] 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks (0) | 2023.07.20 |
| KPConv: Flexible and Deformable Convolution for Point Clouds (0) | 2023.07.04 |



