Paper Overview
WACV'20
https://arxiv.org/abs/1912.07161
Transductive Zero-Shot Learning for 3D Point Cloud Classification
Zero-shot learning, the task of learning to recognize new classes not seen during training, has received considerable attention in the case of 2D image classification. However despite the increasing ubiquity of 3D sensors, the corresponding 3D point cloud
arxiv.org
Abstract
이 논문은 transductive Zero-Shot Learning (ZSL),
Generalized Zero-Shot Learning (GZSL)을 3D point cloud classification에 적용하였다.
이를 위해 새로운 triplet loss가 제안되었고
이 방식은 2D image classification에도 적용이 가능하다.
Keywords
Zero-Shot Learning, Generalized Zero-Shot Learning, Classification, Transductive GZSL
Introduction
2D domain에서 ZSL 방법은 ResNet과 같은 큰 pre-trained model의 이점을 활용할 수 있다.
그러나 3D에서는 그런 모델이 존재하지 않는다.
다라서 이것은 projection domain shift의 문제를 야기한다.
즉, 이것은 seen sample로부터 학습된 함수가 편향되고
unseen에 대해 잘 일반화 할 수 없다는 것을 의미한다.
Inductive learning 접근법에서,
projected semantic vector는 seen feature vector로 편향되는 경향이 있다.

(a)는 2D, (b)는 3D이고 (c)는 inter-class간의 feature 거리를 보여준다.
3D feature의 퀄리티가 2D에 비해 떨어지는 것을 확인할 수 있다.
저자들은 transductive 방식으로 모델의 bias를 줄이고,
projected semantic vector를 true feature vector에 align하기 위해
intra-class 거리를 줄이는 것을 목표로 한다.
이를 위해 unsupervised 방식이 적용된 triplet loss를 제안한다.
Transductive ZSL for 3D Point Clouds
앞서 3D 모델의 feature 퀄리티가 떨어진다고 했는데
tSNE로 시각화 하면 다음과 같다.

이처럼 3D feature는 안정적이지 않고 잘 분리되지않는다.
따라서 대응되는 semantic vector를 projection 하는 것이 2D에 비해 어렵다.
3.1 Problem Formulation

3.2. Model Training
inductive ZSL에 대해, 모델은 seen instance만을 활용하여 모델을 학습한다.

$N$은 배치 내의 intance의 수다.
$\varphi$는 $X$에 대한 featuer vector이고, $\Theta$는 학습할 매핑 함수다.
transductive 방식을 적용하여 다음과 같이 최종 loss를 구성한다.

Transductive ZSL은 domain의 차이를 줄이고 결과적으로 bias를 줄여
일반화 성능을 높일 수 있다.
그 영향은 다음과 같이 확인할 수 있다.

3.3 Unsupervised Triplet Loss
transductive라 하더라도 label이 없기 때문에 triplet loss를 사용하기 위한
lebel을 만들어야 한다.
먼저 저자들은 pseudo-labeling 접근법을 사용하여 positve sample을 정의한다.
각 $X^{u}$에 대해 positive sample $e^{+}$를 선택하기 위해
projection 후 가장 가까운 anchor feature vetor $\varphi(X^{u})$를 선택한다.

GZSL에서는 다음과 같이 선택할 수 있다.

단 negative sampe은 seen semantic embedding에 대해서만 선택된다.
왜냐하면 seen set에 대해서는 반드시 unseen과 다르다는 것을 알 수 있기 때문이다.

이를 활용하여 다음과 같이 $L_{u}$를 구할 수 있다.

최종적인 알고리즘은 다음과 같다.

3.4. Model Architecture
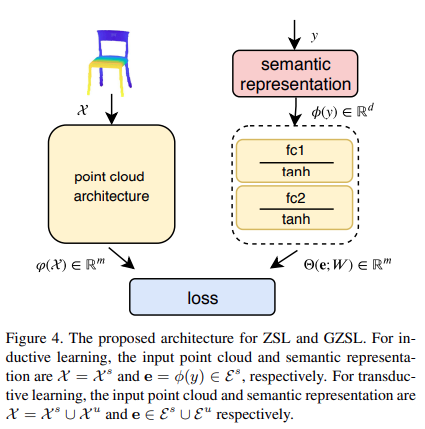
저자들은 point cloud 모델을 PointNet을 활용한다.
3.5. Inference


(7)은 ZSL, (8)은 GZSL이다.
Results
4.1. Experimental Setup
Datasets
ModelNet10, ModelNet40, McGill, SHREC2015, CUB, AWA2를 사용한다.

Semantic feature
3D에 대해서는 300-dimension W2V를 사용하고
2D는 dataset의 attibute를 사용한다.
Evaluation
기본 Acc외에 다음과 같이 harmonic score를 구한다.

Cross-validation
하이퍼 파라미터 값을 구하기 위해 cross-validation 실험을 하고
총 10번 반복해서 평균을 측정한다.
seen data의 N%를 떼어내서 validation set을 구한다.
Implementation details

4.2. 3D Point Cloud Experiments



4.3. 2D Image Experiments


4.4. Discussion
Challenges with 3D data
최근 deep learning 기술로는 point clouds classification 성능이
90%를 뛰어넘는다.
하지만 결과적으로 Zero-Shot에 대해서는Model net 기준 46.9% (vs95.7%)로
성능저하가 크게 발생한다.
좋게 말하면 앞으로 성능 향상의 여지가 많다는 것이다.
2D ZSL에서도 그당시 SOTA가 Image net에 대해서 31.1%이기 때문에
ZSL에서 성능이 떨어지는 건 일반적인 현상이기도 하다.
Hubness
저자들은 semantic vetor를 input feature vector로 projection한다.
이것은 S->I 보다 hubness problem을 약간 완화시킨다.

Conclusion
In this paper, we identified and addressed issues that arise in the inductive and transductive settings of zero-shot learning and its generalized variant when applied to the domain of 3D point cloud classification. We observed that in the 2D domain the embedding quality generated by the pretrained feature space is of a significantly higher quality than that produced by its 3D counterpart, due to the vast difference in the amount of labeled training data they have been exposed to. To mitigate this, a novel triplet loss was developed that makes use of unlabeled test data in a transductive setting. The utility of this method was demonstrated via an extensive set of experiments that showed significant benefit in the 2D domain and established state-of-the-art results in the 3D domain for ZSL and GZSL tasks.
Supplementary Material
6. Additional Quantitiative Evaluation
6.1. Batch Size

6.2. Point Cloud Architecture


6.3. QFSL's Generalized ZSL Evaluation Protocol
ZFSL protocol에서, seen, unseen instance로 구성된
unlabeled data는 반으로 나누고 두 모델이 학습된다.
각 모델은 unlabeled data의 반은 학습하고 반은 테스트 한다.
최종 성능은 두 모델의 성능을 평균내는 것이다.

7. Qualitative Evaluation


'Zero-Shot Learning > 3D Classification' 카테고리의 다른 글
| [논문리뷰] Zero-Shot Learning on 3D Point Cloud Objects and Beyond (0) | 2024.04.16 |
|---|---|
| [논문리뷰] Mitigating the Hubness Problem for Zero-Shot Learning of 3D Objects (0) | 2024.03.05 |

