정보나 추세를 찾기 위해 논문의 실험은 빠뜨리고 읽었는데
밑빠진 독에 물만 한 1년치 부었던 것 같다.ㅋㅋ
논문의 실험을 직접 할 거 아니면
무조건 실험 파트를 읽고 insight를 얻는게 좋을것 같다.
ICML'20
https://arxiv.org/abs/2003.06957
Frustratingly Simple Few-Shot Object Detection
Detecting rare objects from a few examples is an emerging problem. Prior works show meta-learning is a promising approach. But, fine-tuning techniques have drawn scant attention. We find that fine-tuning only the last layer of existing detectors on rare cl
arxiv.org
Abstract
저자들은 기존에 개발된 detector들의 last layer만 fine-tuning하는 것이
few-shot object detection task에 중요하다는것을 알았다고 한다.
그래서 간단한 접근법으로 기존 benchmark의 2~20 point를 넘겼다고 한다.
근데 기존 benchmark는 성능 변동성이 커서 믿기 어렵기 때문에
자기네들이 새로운 benchmark 측정법을 제안했다고 한다.
본 모델은 타 논문에서 [TFA] 라고 불리는 모델이다.
1. Introduction
기존 evaluation protocol은 통계적인 불신성(unreliability) 때문에 문제가 있다.
그래서 baseline이라는게 안정적이지 않다.
그래서 저자들은 새로운 evaluate method를 제안했다.
저자들은 training schedule과 detector의 instance-level feature normalization에
초점을 맞췄다고 한다.
새로운 evaluate는 모든 class의 AP 말고도
base와 novel을 구분한 AP도 보여준다고 한다.
(앞으로 이것은 few-shot OD에서 bAP, nAP로 통용된다.)
또 저자들은 다음 그림과 같이 two-stage training 전략을 사용했다.

일단 object detector로 Faster R-CNN을 사용한다.
base dataset은 충분하게 novel dataset은 적게 가져간다.
detector의 last layer만 fine-tuning하고 나머지는 freezing한다.
fine-tuning stage에서 box classifier에
instance-level feature normalization하는것을 소개한다고 한다.
3. Algorithms for Few-Shot Object Detection
저자들은 meta-YOLO의 few shot object detection settings을 따라간다고 한다.
base class는 Cb, novel class는 Cn이며 보통 카테고리당 K instances를 가진다고 한다.
dataset을 D = {(x, y)}라 할 때, x는 input image y는 class c와 bounding box좌표 I를 나타낸다.
PASCAL VOC와 COCO를 사용하는 few-shot dataset에서,
training하는동안 novel set은 균형이 잡혀있고 각 class는 같은수의 object를 가진다.
또 최근 LVIS datset은 long-tail 분포를 가지기 때문에 일반적인 K-shot split이 안된다.
그래서 LVIS의 class는 100개 이상의 이미지가 나타내는 frequent class와
10~100개의 이미지가 나타내는 common class
10개 이하의 이미지가 나타내는 rare class로 구분한다.
few-shot object detector는 bass class와 novel class 모두에서 평가된다.
이 task의 최종 목표는 novel calss의 AP도 좋게 만드는 것이다.
(few-shot classification의 N-way-K-shot setting과는 다르다는 것을 인지해야 한다.)
3.1. Two-stage fine-tuning approach
저자들은 Faster R-CNN을 사용했다.
직관적으로, backbone feature와 RPN feature는 class-agnostic이라고 한다.
(그러나 2021년 후속 연구에서 class-agnositc이 아니라고 밝혀진다.)
그러므로 base class로부터 학습된 featuer는 파라미터 업데이트 없이 그냥 transfer해도 된다고 한다.
이 연구의 키 포인트는 feature representation learning과 box predictor leanring을 분리하는 것이다.
Base model training
모델 학습의 첫번째 단계는 feature extractor와 box predictor를
bass class Cb만으로 학습하는 것이다.

Lrpn은 background로부터 foreground를 구분하고 anchor를 정제(refine)한다.
Lcls는 box classifer C의 cross-entropy loss다.
Lloc는 box regressor R의 smoothed L1 loss다.
Few-shot fine-tuning
모델 학습의 두번째 단계에서 bass와 novel의 균형잡힌 training set을 만들고
box prediction network에 랜덤 초기 weight를 할당한 뒤에 fine-tune을 하는 것이다.
fine-tuning을 할 때 base에서 사용한 기존 classifier는 지우고 새로운 classifer를 부착한다.
이때 feature extractor F는 고정시킨다.
loss는 위의 (1)식을 그대로 사용한다.
learning rate는 첫번째 단계 대비 1/20로 줄인다.
(논문에서는 단순 20이라 적혀있으나 실험파트를 보면 1/20임을 알 수 있다.)
Cosin similarity for box classifier
저자들은 fine-tuning 단계에서 cosine similarity에 기반을 둔 classifier 사용을 고려한다.
box classifer C의 weight matrix W ∈ R(dxc)를 [w1, w2, ... , wc]라고 쓸 수 있다.
(wc ∈ R(d) 는 class당 weight vector다.)
ouput C는 input feature F(x)와 다른 class weight vector의
similarity score S로 스케일링 된다.

sij는 input x의 i번째 object proposal과 class j의 weight vector사이를 나타낸다.
α는 20이다.
저자들은 실증적으로 위 s를 사용한 instance-level feature normalization이
intra-class variance를 줄이고 novel class의 정확도를 높이는데
도움을 주는것을 알았다고 한다.
(FC-based classifier랑 비교해서 더 좋다.)
3.2. Meta-learning based approaches
저자들은 FSRW, Meta R-CNN, MetaDet 같은 meta learning 기반 모델도
저자들이 제안한 방법으로 평가하고자 한다.
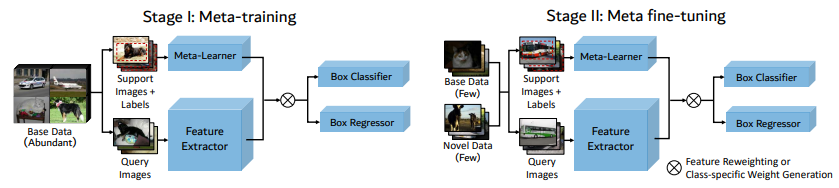
meta-learning 접근법에서 meta-learner는 task-level meta information을 습득하고
feature re-weighting이나 weight generation을 통해 novel class에 모델을 일반화 되도록 돕는다.
meta learner로의 input은 target object의 bounding box annotation이 있는
support image의 작은 집합이다.
base object detector and the meta-learner는 종종 episodic training을 사용하여 같이 학습된다.
(Matching networks for one shot learning 참고하라고 한다.)
FSRW, Meta R-CNN support image와 binary mask는 meta-learner의 input으로 사용된다.
meta-learner는 query image의 feature 표현을 모듈화하는 class reweighting vector를 만든다.
학습절차는 그림 2와 같이 meta-training, meta fine-tuning stage로 구분된다.
그러나, 저자들은 위 방법이 메모리를 매우 비효율적으로 쓴다는 것을 발견했다.
저자들이 제안한 방법은 마지막 layer만 학습하므로 훨씬 효율적인 메모리 사용이 가능하다고 한다.
4. Experiments
Implementation details
저자들은 Faster R-CNN을 base detector로 쓰고
Feature Pyramid Network가 부착된 Resnet-101을 backbone으로 쓴다.
optimizer는 SGD를 쓰고
Batch size는 16, momentum은 0.9, weight decay는 0.0001
learning rate는 0.02 (base training), 0.001 (fine-tuning)을 쓴다.
4.1. Existing few-shot object detection benchmark
Existing benchmarks
선행연구를 따라 PASCAL VOC 2007+2012, COCO에 대해 평가한다.
data split 방법은 Meta-YOLO를 따른다.
FASCAL VOC에서 2007+2012 trainval set의 20 class를 랜덤으로 15:5로 나눈다.
K는 1,2,3,5,10으로 해서 K per image로 한다.
PASCAL VOC 2007 test set을 평가에 사용한다.
COCO는 일단 PASCAL과 안겹치는 class 60개를 base로 사용하고
나머지 20개를 novel로 사용한다. K는 10, 30이다.
AP는 50을 기준으로 평가한다.
Baselines
+joint 는 base와 novel class가 one stage에 joint로 학습되고
전체 모델을 fine-tuning한다는 뜻이다.
+ft-full은 feature extractor F와 box predictor C, R이
joint로 second fine-tuning stage에서 수렴할 때 까지 fine-tuning된다는 뜻이다.
+ft는 반복횟수를 줄인 fine-tuning이다.
Faster R-CNN을 FRCN으로 줄여 썼다.
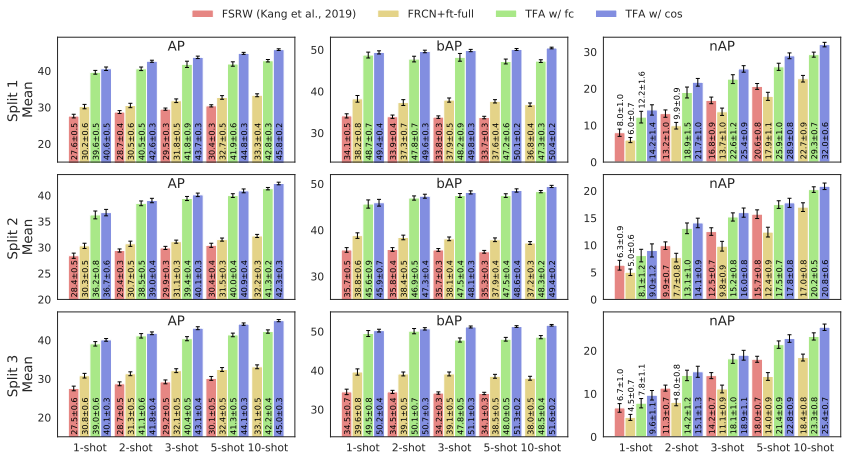
Results on PASCAL VOC

mAP50기준으로 3가지 random split을 통해 novel class를 구성하였다.
앞서 언급한것 처럼 ResNet-101을 backbone으로 사용하여 실험하였다.
(Meta R-CNN처럼 FRCN+ft-full을 했다고 하는데 이것은 추후에
Meta R-CNN을 읽고 추가하겠다.)
실험을 해보니 MetaDet은 VGG16을 쓰는데 가끔 Meta R-CNN보다 안좋게 나왔다고 한다.
실험 결과 저자들의 모델이 훨씬 좋았다고 한다.
조금 더 디테일한 결과는 다음과 같다.

이 논문부터 Base AP, Novel AP를 구분하여 평가하기 시작했다.
결과적으로 novel class에 대해 이전 연구보다 훨씬 좋은 결과를 기록했다.
Results on COCO
COCO dataset은 AP75를 기준으로도 실험했다.

실험 결과 제안된 모델이 가장 좋다.
4.2. Generalized few-shot object detection benchmark
Revised evaluation protocols
기존 연구 benchmark는 몇가지 문제가 있다.
먼저 novel class에 초점을 맞춰 성능을 평가하여 base class 성능저하는 무시했다.
그래서 bAP, nAP를 제안했다고 한다.
두번째는 샘플 변동성 때문에 성능이 일정하지 않기 때문에 모델간의 성능 평가로
어느 모델이 더 좋다고 평가하는것은 어렵다고 할 수 있다.
저자들은 평균과 신뢰 구간을 얻기 위해 training shot의
서로 다른 랜덤 샘플을 실행시켰다.
서로 다른 랜덤 샘플이란 기존 benchmark와 달리 novel class를 계속 바꿔주는것이다.

위 결과를 보면 한 30번은 실행시켜야 결과가 안정된다는것을 확인 할 수 있다.
자세한 결과는 부록B를 참조하자.
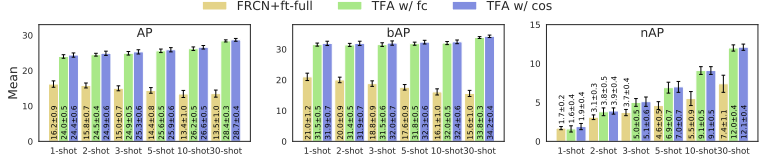
Results on LVIS
저자들은 본 모델을 최근 만들어진 LVIS 데이터셋에 실험했다고 한다.
LVIS는 실제 자연과 유사한 long-tail 분포를 가지고 있다.

그래서 head쪽을 base class, tail쪽을 novel class로 했다고 한다.
base training은 앞선 VOC같은 데이터셋 학습과 똑같이 했고
fine-tunig은 전체 이미지에서 인위적인 subset(10 instance까지)을 만들어 진행했다.
결과는 다음 표와 같다.

실험은 LVIS데이터셋 논문에서 주장한것처럼 weighted sampling을 적용했다고 한다.
실험 결과 repeated sampling없이도 저자들의 two-stage fine-tuning 전략이
data imbalance 문제도 다둘 수 있다는 것을 알았다.
Results on PASCAL VOC and COCO
저자들은 Generalized few-shot 실험을 했다.
기존 benchmark는 split당 novel class를 특정 class로 고정시켜두고 실험하는것이고
Generalized는 novel class를 바꿔가며 여러번 실험하는 것이다.
이때 신뢰구간은 95%로 하는데 아래 부록A를 참조하면 된다.
전반적으로 TFA가 좋다.
4.3. Ablation study and visualization
Weight initialization
weight 초기값을 2가지 케이스에 대하여 실험했다고 한다.
(1) random initialization
(2) fine-tuning a predictor on the novel set and using the classifer's weight
실험 결과는 아래 표와 같다.

PASCAL VOC는 (1)이 좋고
COCO는 (2)가 좋았다고 한다.
이것은 확률적으로 COCO가 class가 많아 더 복잡하기 때문이라고 한다.
따라서 VOC는 (1)로 실험하고 COCO, LVIS 실험에는 (2)로 실험했다고 한다.
Scaling factor of cosine similarity
cosine similarity α를 10,20,50으로 실험해본 결과 다음 표와 같았다.

α는 20이 가장 좋았다고 한다.
Detection result
검출 결과는 다음과 같다.

5. Conclusion
저자들은 간단한 few-shot object detection의 two-stage fine-tuning 접근법을 제안했다.
그리고 신뢰할 수 있는 benchmark protocol을 제안했다.
부록A. Generalized Object Detection Benchmarks
우선 저자들은 PASCAL과 COCO에 대한 full benchmark 결과를 보여준다.
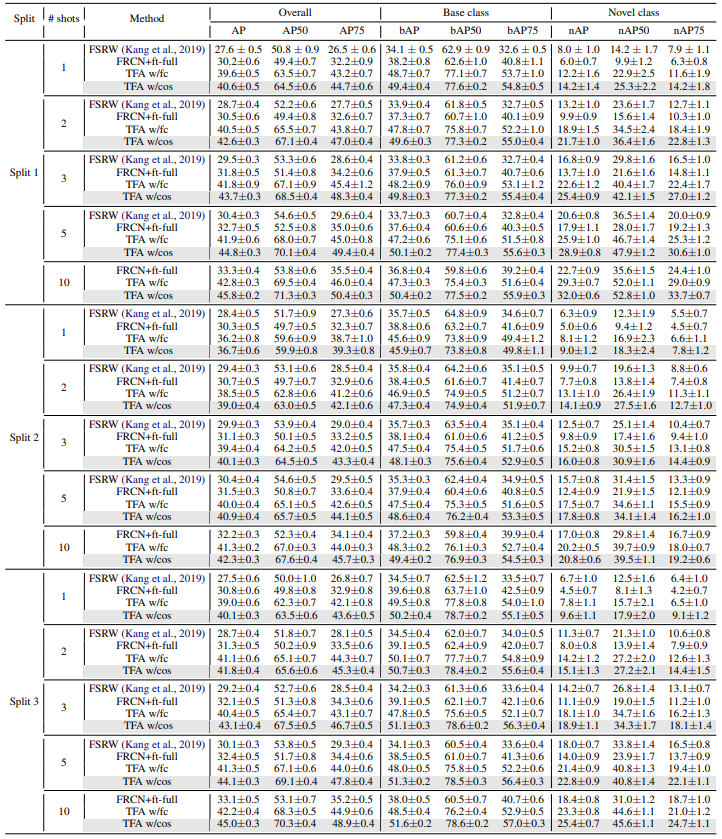

위 표에서 볼 수 있듯이 AP를 세분화 하여 실험하였다.
AP는 average AP를 뜻한다.
그리고 앞서 언급한것처럼 Generalized 실험을 위해 총 30번(VOC) 또는 10번(COCO)의 실험을 하고
(novel set 구성을 계속 바꿔가며..)
95% 신뢰 구간은 다음과 같이 계산했다고 한다.

1.96은 Z-value, s는 standard deviation, n은 반복 횟수다.
전반적으로 TFA에 cos를 추가한 것이 성능이 좋다는것을 볼 수 있다.
부록B. Performace over Multiple Runs
Genralized 실험을 위해 반복 횟수를 정하는 실험을 했다.


본 논문은 few-shot object detection에 대한 benchmark를
이해하기 위해 필수로 살펴봐야 하는 논문이라 생각한다.