요즘 개강으로 인해 논문 읽기가 쉽지 않다..
최대한 틈틈히 해야겠다.
이 논문은 요즘 성능이 좋은 모델인 DETR의 v1 논문이다.
ECCV'20
https://arxiv.org/abs/2005.12872
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
기존의 Object Detection 모델들은 예측을 할 때 간접적인 방법으로 object를 검출한다.
(예를 들어 proposals, anchors, window centers.. 등)
저자는 기존 방법과 다르게 direct로 prediction approach를 하는 방법을 제안한다.

저자는 모델이 prediction problem을 direct로 처리하면서 위와 같이 training pipeline을 줄였다.
위에 보이는것 처럼, transformer를 기반으로 한 encoder-decoder 구조를 도입했다.
위와 같은 모델을 DEtection Transformer (DETR)이라고 한다.
DETR은 모든 물체를 한번 prediction 하고
예측값과 ground-truth와 bipartite matching을 하는 loss를 통해 end-to-end 방식으로 학습한다.
DETR은 bipartite matching loss와 병렬 decoding을 하는 transformer의 결합이다.
matching loss function은 ground truth에 고유하게 할당되고 예측 permutation(순열)에 불변하기 때문에 병렬 처리가 가능하다.
DETR은 상당한 성능 개선을 이루었지만 작은 물체에 대해서는 low perfomance를 기록하였다.
DETR은 또 extra-long training schedule과 transformer의 보조 decoding loss의 benefit을 필요로 한다.
다음의 두 요소는 direct set(집합) prediction에 필수적인 요소라고 한다.
1. 예측과 ground truth box의 고유한 matching을 강제하는 set prediction loss
2. single pass로 객체의 set(집합)을 예측하고 그것들의 relation을 모델링하는 architecture
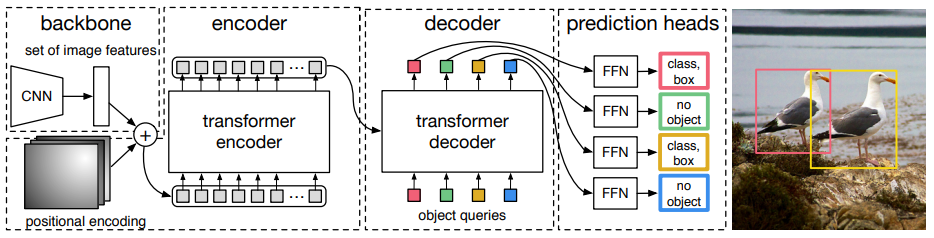
위 그림은 DETR의 architecture다.
먼저 위의 1번 요소인 Object detection set prediction loss부터 살펴보겠다.
DETR은 single pass로 decoder을 통해 고정된 사이즈의 N개의 예측 집합을 추론한다.
(N은 이미지 안에 있는 object의 수보다 상당히 더 크게 설정된다.)
loss는 예측과 ground truth 사이의 최적화된 bipartite matching을 만들고 object-specific (bounding box) loss를 최적화 한다.
N은 이미지 안에 있는 object의 수보다 더 크게 설정되므로,
y도 ∅로 채워진 N크기의 set으로 여길 수 있다. (y는 ground truth set)
따라서 N개의 집합 elements인 σ ∈ S 를 search하여 두 sets(예측, GT)의 bipartite matching을 찾는다.
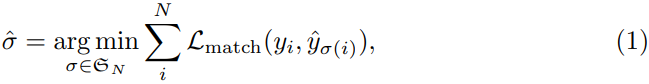
Lmatch는 index σ(i)의 GT와 예측사이의 matching cost다.
이것은 Hungrian algorithm을 사용하여 효과적으로 계산한다고 한다.
index σ(i)의 예측에 대해 class c에 대한 확률을 pσ로 정의하고 box 예측을 bσ로 정의하면,
Lmatch는 다음과 같의 정의된다.
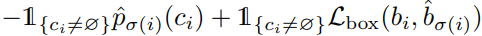
이 matcing을 찾는 절차는 proposal이나 anchor (modern detector model)같은 heuristic assignment 역할을 한다.
가장 큰 차이점은 object를 중복없이 예측 set을 direct로 one-to-one 방식으로 찾는것이다.
(윗 줄의 설명은 차후 공부를 더 한 뒤 (6개월 정도?), 구체적으로 어떻게 차이나는지 서술할 예정)
위 처럼 matching을 한 뒤에 Hungarian loss를 계산한다.

σ는 위의 (1)식에서 구한 것이다.
이것은 Faster R-CNN의 subsampling을 통한 balance proposals 학습 절차와 유사하다.
위 Loss는 객체와 ∅의 matching cost는 예측에 의존하지 않고, 이 cost가 상수라는 것을 강조한다.
이 matching cost에서 log확률 대신에 pσ를 사용하고, 이로 인해 box loss를 균형잡힌 class 예측 term으로 만든다.
Bounding box loss에서는 loss의 relative scaling에 대한 문제를 완화하기 위해,
IoU loss와 L1 norm의 선형 결합을 사용하여 scale-invariant하게 만든다.
따라서 L box는 다음과 같이 정의한다.

λiou, λL1은 하이퍼 파라미터다.
이제 위의 2. 요소인 architecture을 보자.
위 architecture 그림을 보면 DETR은 3가지 요소로 구성돼있다는 것을 알 수 있다.
1. CNN backbone
2. encoder-decoder transformer
3. simple feed forward network (FFN)
일반적인 detector와 다르게 DETR은 CNN backbone과 transformer 구현부만 제공하면 단 몇백줄로 구현이 가능하다고 한다.
거기다 추론 단계는 Pytorch로 대충 50줄로 구현이 가능하다 한다.
그래서 저자들은 이 DETR이 새로운 연구의 패러다임을 가져와주길 바란다고 한다.
Backbone에서 이미지 x는 다음과 같이 구성되고

CNN backbone을 통해 다음과 같은 저해상도 activation map을 만들어낸다고 한다.

(전형적인 value로 C = 2048, H = H0/32, W = W0/32를 사용한다.)
Transformer encoder에서
먼저 1x1 convolution으로 high-level activation map f 차원(C)을 d로 축소시켜 새로운 feature map z0를 만든다.
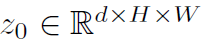
각 encoder layer는 일반적인 구조를 가지고 multi-head self-attention 모듈과 feed forward network (FFN)으로 구성돼있다.
transformer 구조가 permutation-invariant이기 때문에,
저자는 이것을 각 attention layer의 input이 추가되고 고정된 positional encoding으로 보완한다.
Transformer decoder에서
multi-head self attention, encoder-decoder attention 매커니즘을 사용하여 사이즈 d의 임베딩N을 변환하는 표준 transformer 구조를 따른다.
「Attention Is All You Need」라는 논문의 transformer는 한번에 한element를 예측하는 autoregressive 모델을 사용하는 반면, DETR은 각 decoder layer에서 병렬적으로 N개의 object를 decode한다.
decoder는 permutation-invariant이기 때문에 N input embedding이 달라야 다른 결과를 생성할 수 있다.
이러한 input embedding은 object query라고 하는 학습된 positional encoding이며,
encoder와 유사하게 각 attention layer의 input에 추가한다.
N object query는 decoder에 의해 output embedding으로 transform된다.
이것들은 feed forward network에 의해 box 좌표와 class label이 독립적으로 decode된다.
(결과적으로 N개의 최종 예측이 생김)
이러한 embedding을 넘어 self attention과 encoder-decoder attention도 사용하기 때문에,
DETR은 전체 이미지를 context로 사용할 수 있는 동시에 pair-wise relation을 사용하여 모든 개체에 대해 전체적으로 추론한다.
feed-forward network (FFN)의 예측에서
최종 예측은 ReLU와 hidden dimention d와 linear projection layer과 함께 3-layer perceptron으로 계산된다.
FFN은 box의 normalized 중심 좌표, height, width를 예측하고 선형 layer는 softmax 함수를 사용하여 class label을 예측한다.
DETR은 N개의 bounding box의 고정된 집합을 예측하기 때문에, 추가적인 class label ∅는 no object라고 한다.
∅는 object detection 접근의 background class같은 역할을 한다.
초반에서 보조적인(auxiliary) decoding loss가 필요하다고 했다.
이것은 특히 모델의 각 class별 정확한 숫자의 object를 찾는데 도움을 준다고 한다.
각 decoder layer의 output은 shared layer-norm으로 정규화된 다음 shared prediction head(classification과 box prediction)에 공급된다.
그런 다음 supervision을 위해 Hungarian loss를 적용한다.
이 논문은 기존의 다중 layer 방식의 detector와는 다르게 transformer라는 것을 사용하여
object detection task를 한 모델이다.
이 모델을 기반으로 만들어진 detector가 최근 최고의 정확도를 자랑하고 있다.
그러나 이런 DETR은 학습하는데에 막대한 시간이 걸리며 (RTX 2080ti한대 기준 1epoch당 3시간 30분 정도, 총 300 epoch 필요) 모델의 크기도 막대하다.
실제로 마이크로소프트에서는 tesla v100을 8대를 병렬처리해서 연구하고 있다.
아마 제가 속해있는 대학 규모의 연구실에서는 transformer연구가 매우 어렵지 않을까 싶다.
이번에는 transformer에 대한 지식이 부족하여 되게 난해하게 공부하였는데 차후 여러 논문을 보며 개선하도록 하겠다.
'AI Technology > Object Detection' 카테고리의 다른 글
| Focal Loss for Dense Object Detection 리뷰 (1) | 2022.08.22 |
|---|---|
| Dynamic Head: Unifying Object Detection Heads with Attentions 리뷰 (1) | 2022.08.08 |

