드디어 3학년 2학기가 끝났다
학부 18학점에 대학원 강의 3학점 해서 총 21학점 들었는데
7전공 하니까 평점이 멸망해 버렸다ㅋㅋㅋ
그래도 덕분에 4학년때 얼마 안들어도 될듯ㅎ
CVPR'19
https://arxiv.org/abs/1904.11245
Exploring Object Relation in Mean Teacher for Cross-Domain Detection
Rendering synthetic data (e.g., 3D CAD-rendered images) to generate annotations for learning deep models in vision tasks has attracted increasing attention in recent years. However, simply applying the models learnt on synthetic images may lead to high gen
arxiv.org
이 논문은 Mean Teacher 구조를 업그레이드 시킨 논문이다.
그래서 저자들이 모델 이름을 MTOR(Mean Teacher with Object Relations)으로 정했다.
간단히 요약하자면 Teacher과 Student 모듈의 consistency에 초점을 맞춘 모델이다.
3가지 regularizations이 있다.
1. region-level consistency
2. inter-graph consistency
3. intra-graph consistency

전체적인 구조는 위와 같다.
모든 Domain adaptation 논문이 공통적으로 말하는 성능 저하의 원인은
데이터 분포의 "domain shift" 현상이다.
이것을 어떻게 완화시키느냐가 이쪽 연구의 목표라고 보면 된다.
이 저자들은 이것을 Mean Teacher 구조로 해결하려 했다.
먼저 Mean Teacher 모델을 살펴보면
크게 Student 모델 fs(파라미터 wfs)와 Teacher 모델 fT(파라미터 wft)가 있다.
메인 아이디어는 input이나 network 파라미터의
작은 동요(perturbation)에 일관성 있는 예측을 하도록 만드는거다.
그래서 다음과 같은 Mean Squared Error를 정의한다.

이때 student 모델은 gradient descent를 통해 파라미터가 업데이트 되고
teacher 모델은 exponential moving aveage 업데이트를 한다.
따라서 위 consistency loss를 포함한 최종 loss는 다음과 같다.
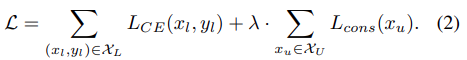
여기서 consistency 파트를 변형할 것이다.
이제 문제 정의가 필요하다.
일단 데이터는 Ns개의 레이블이 있는 데이터Ds와
레이블이 없는 Dt가 있다.
Ds를 source domain, Dt를 target domain이라고 한다.
이때 Ds의 데이터 xs는 supervised 모델인 student에 들어가고
Dt의 데이터 xt는 2개 샘플 xtT, xtS로 augmentation 된다.
그리고 xtS는 student, xtT는 teacher로 들어간다.
이 xT로 consistency를 측정한다고 한다.
Region-Level Consistency는
local instance variances를 줄여주는데 도움을 준다고 한다.
xtT와 xtS는 같은 backbone(Faster R-CNN)으로 입력된다.
그리고 xtT의 base feature map과 region proposal은 다음과 같다.

각 region proposal은 다음과 같다.
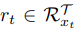
그리고 각 region의 예측(확률)은 background와 foreground 카테고리의
distribution 확률이다.

따라서 전체 detection output은 다음과 같다.

xtS도 같은 방식으로 정의된다.

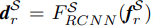
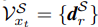
이렇게 S와 T의 V가 나오는데 이것을 사용해서
region-level consistency를 측정한다.
일단 모든 region을 사용할 수는 없으니 (잘못된 region도 있기 때문)

를 계산해서 이 q값이 임계값 𝜖 보다 작으면 그 region은 지운다.
C는 클래스다.
이렇게 d를 전처리 하고 Region-level Consistency Loss (RCL)에 적용한다.
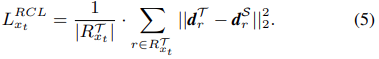
Inter-Graph Consistency는
teacher과 student의 region proposal의 예측을 align한다.
teacher과 student의 그래프의 affinity matrices를 매칭함으로써
input의 동요(perturbation)의 consistency를 측정한다.
relational graph는 다음과 같이 구성된다.
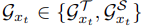

사이즈는 다음과 같다.

여기서 V는 아까 전에 언급한 d의 집합이고, ε가 affinity matrices다.
이렇게 ε는 다음과 같은 cosine similarity를 통해 구해진다.
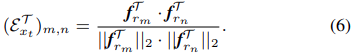

εS도 같은 방식으로 구해니고 이 둘을 합쳐서
IntEr-Graph Consistency Loss(EGL)를 구성한다.

마지막으로 Intra-Graph Consistency는
같은 클래스에 대해 student와 teacher의 consistency를 강화해준다.
target sample은 레이블이 없기 때문에,
teacher을 직접 이용해서 각 region proposal에 pseudo label을 할당한다.
pseudo label은 다음과 같다.
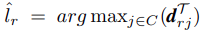
그 다음 supervision matrix M을 만든다.
M은 두 region 이 같은 카테고리에 속해 있으면 다음과 같이 만들어진다.
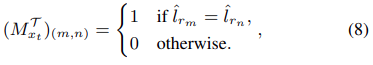
사이즈는 다음과 같다.

이렇게 affinity matrix와 supervision matrix를 구하면
intrA-Graph consistency Loss(AGL)을 구할 수 있다.

이 값이 작아질수록 같은 pseudo label을 가진 region의 거리는 가까워 진다.
최종 Loss는 다음과 같다.

teacher의 가중치는 다음과 같이 업데이트 된다.

이 논문은 Mean Teacher에 consistency요소를 추가하여 만든 모델이다.
target이미지를 2종류의 새 이미지로 만들어서 학습시킨다는 점이 독특하다.
region-level consistency에서 local variance를 줄였다.
inter-graph consistency에서 teacher과 student의 일관성을 유지시켰다.
intra-graph consistency에서 같은 클래스에 대해 일관성을 향상시켰다.



