시간이 너무 잘 간다.
이젠 정말 진짜 선택과 집중이 중요해진것 같다고 느껴진다.
대학 졸업까지 1년, 학석사로 석사기간 1년 반
2024년 2월 학부 졸업, 2025년 7월 석사 졸업이 연달아 있어서
바쁘다.
ICLR'18
https://arxiv.org/abs/1803.07728
Unsupervised Representation Learning by Predicting Image Rotations
Over the last years, deep convolutional neural networks (ConvNets) have transformed the field of computer vision thanks to their unparalleled capacity to learn high level semantic image features. However, in order to successfully learn those features, they
arxiv.org
이 논문은 회전된 이미지가 들어왔을 때 그 각도(2D 변화)를 예측하는 논문이다.
저자들은 self-supervised paradigm을 따랐다고 한다.
먼저 discrete geometric transformation set을 정의하고 각 geometric transformation이
이미지에 적용되도록 하고 그 이미지를 ConvNet의 입력으로 넣었다.
이미지는 다음과 같이 4개의 각도로 정의했다. (4-way classification)

위와 같은 이미지의 회전된 각도를 예측하는것이 본 논문의 목적이다.
계속 강조하지만, 본 논문의 목적은 unsupervised manner로 semantic features를 기반으로
ConvNet model F(·)를 회전된 각도를 출력하도록 학습하는 것이다.
K- discrete geometric transformation를 다음과 같이 정의한다.


여기서 y는 각도 label이다.
모델 F는 따라서 input Xy가 들어왔을 때 다음과 같이 각 rotaion 확률을 출력한다.

우측 항의 Fy는 이미지가 label y일 확률을 뜻한다.
y*은 미지의 값 (unknown)이라는 뜻이다.
그러므로, 다음과 같이 N개의 이미지가 들어오면 self-supervised training은 다음과 같다.

위의 loss 함수는 다음과 같이 정의 된다.
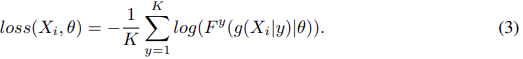

본 논문은 위에서 잠깐 언급했지만
rotaion transformation을 90도의 배수 (0,90,180,270)으로 각도를 정의하였다.
Rot(X, φ)를 ratate image X, 각도 φ라고 하면 위의 g(X|y)는 다음과 같다.

Forcing the learning of semantic features
이미지의 각도를 효과적으로 예측하는것은
이미지 class를 구분하도록 semantic part를 먼저 학습하지 않는 한 근본적으로 불가능한 task다.
이를 위해, 모델이 각도 예측을 성공하기 위해서는 중요한 object를 localize하고
object의 type과 orientation을 인식하도록 하고
각 이미지의 dominant orientation에 대해 object orientation과 연관시키도록 반드시 학습해야 한다.
다음 예를 통해 위 문장을 쉽게 이해할 수 있다.
input으로 다음 이미지가 들어가면

supervised 방식으로 image class를 구분하도록 할 때 모델의 Attention map은 다음과 같다.

self-supervised 방식으로 image의 rotation을 구분하도록 하는 모델의 Attention map은 다음과 같다.

두 attention map이 비슷하다는 점으로 결국에는 각도예측도 이미지의
semantic한 특성을 학습하게 돼있다는 것이다.
(하지만 실험에 따르면 rotation 예측에 필요한 feature와
class 예측에 필요한 high-level feature는 다르다라는 것을 알 수 있다.)
저자들은 모델이 일반 supervised learning과 computation cost가 비슷하고
특별한 전처리 과정이 필요 없이 학습할 수 있다고 한다.
이 논문은 실험 세팅을 봐야지 정리가 된다.
CIFAL Experiments
먼저 RotNet은 Network-In-Network (NIN) 구조를 사용한다.
NIN이란 다음과 같은 선형 conv. layer를

중간에 MLP를 넣어서 다음과 같이 Mlpconv. layer로 만들어서

다음 그림과 같이 쌓는 것이다.

저자들은 선행 연구에서 training 할 때 한번에 4 방향의 이미지를 모두 보는게
성능이 좋아서 training batch마다 batch size를 4배로 학습한다고 한다.
다음 실험결과는 RotNet을 학습시킨 뒤 각 NIN layer마다 끝에 classifier를 붙여서
classification 성능을 체크하였다.

이 실험 결과에서 알 수 있는것 처럼 layer의 상단부로 갈 수록
rotation과 class의 feature는 다르다는것을 알 수 있다.
다음 실험결과는 각도 수 K를 지정함에 따라 각도 예측 성능이 어떻게 달라지는지 보여준다.

다음 결과는 RotNet의 2번째 layer에 classifier를 달아서 성능 체크한 표인데

RotNet은 각도 feature만 추출했음에도 준수한 성능을 가진다는 것을
알 수 있다.
classifier는 2 hidden layer와 200 feature channels을 가지고
batch-norm relu를 중간에 넣었다고 한다.

(a)에서 self-supervised는 RotNet layer 2 + classifer다.
Rotation을 학습시킬 때 20 epoch마다 freeze시키고 classifier를 학습시켜
recognition accuracy를 수행한다. (매 20 epoch마다 classifer는 새로 학습)
rotation 정확도가 높아짐에 따라 class 정확도도 개선된다는 것을 알 수 있다.
(b)에서는 semi-supervised 실험이다.
training example이 적을 때 RotNet으로 먼저 rotation을 예측하도록 학습하고 (4 layer까지)
classifier를 학습키셨을 경우 1000 examples 이하가 trainset으로 주어졌을때
supervised보다 성능이 좋다는 것을 알 수 있다.
이유는 앞서 언급한대로, 모델이 각도 예측을 성공하기 위해서 중요한 object를 localize하고
object의 type과 orientation을 인식하도록 하고
각 이미지의 dominant orientation에 대해 object orientation과 연관시키도록 학습되는 과정이
object recognition 학습에 도움이 되기 때문이다.
ImageNet 실험도 있는데 이것은 모델이 AlexNet으로 바뀐 것이다.
이 논문은 단순히 Rotation classification 뿐만 아니라
Rotation학습이 일반적인 classification 학습에 도움이 된다는 것을 알 수 있었다.


