Paper Overview
IEEE Signal Processing Letters'21
https://ieeexplore.ieee.org/document/9464653
Request Rejected
ieeexplore.ieee.org
Abstract
저자들은 새로운 semantic encoding out-of-distribution classifier (SE-OOD)를 제안한다.
본 방법은 먼저 semantically consistent mapping을 하여
모든 visual sample을 대응되는 semantic attribute에 project한다.
그 다음 projected visual sample과 원래 semantic attribute 둘다
distribution alignment를 위해 latent representation로 인코딩 된다.
학습된 latent space에서 seen sample로부터 unseen sample을 분리한 다음
two domain classifier (ZSL, supervised)를 적용하여 task를 수행한다.
Keywords
Zero-Shot Learning, Generalized Zero-Shot Learning, Classification, Out-of-distribution classifier
Introduction
GZSL 방식중에서는 gating mechanism이 있다.
이것은 GZSL을 ZSL과 supervision learning task로 분리하는 방법이다.
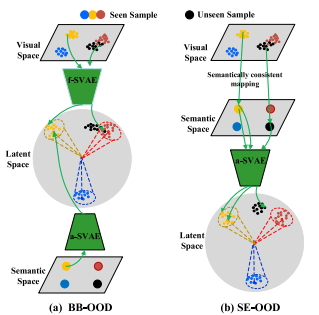
(a) 방법은 unseen visual feature가 seen-similar sample에 대해 헷갈려 하는 문제가 있다.
저자들은 seen-similar visual sample이 이것들의 non-semantic information을 없앰으로써
다뤄질 수 있다고 가정한다.
그러므로 저자들은 (b)와 같은 구조를 제안한다.
저자들의 key ida는 semantically consistent mapping이
seen-similar sample에 대한 부정적 영향을 지우고
unseen class에 더 효과적인 OOD classification을 가능하게 한다고 한다.
Proposed Model
A. Problem Definition
이처럼 3D feature는 안정적이지 않고 잘 분리되지않는다.
따라서 대응되는 semantic vector를 projection 하는 것이 2D에 비해 어렵다.

B. Semantically Consistent Mapping
semantically consistent mapping은
모든 training visual sample이 대응되는 semantic attribute에 project되도록 설계된다.
projected feature는 non-semantic information을 지우는 것으로 예측되고
따라서 다른 class distribution에 덜 헷갈릴 것이라 한다.
따라서 저자들은 다음과 같이 semantically consistent mapping를 한다.

$M$은 mapping fuction, $x_i$는 $i$번째 visual sample, $a_i$는 attribute다.
이 방식으로, seen-similar sample은 unseen sample쪽으로 더 당겨질 것이라 한다.
C. Semantic Encoding Network
semantic encoding network의 목표는 latent space에 있는
seen class에 대한 manifold 경계를 학습하는 것이다.
이를 위해 shared SVAE가 이용된다.


저자들은 더 modality-invariant information을 인식할 수 있도록
cross-reconstruction criterrion을 network에 추가한다.

또 추가적으로, 저자들은 supervised classification loss를
latent variable에 추가하여 encoding의 discriminability를 보존한다.

따라서 최종 loss는 다음과 같다.

전체적인 framework는 다음과 같다.

D. OOD Classifier and GZSL
class center와 boundary를 이용함으로써,
OOD classifier는 seen으로부터 unseen sample을 분리할 수 있다.
먼저 training sample을 대응되는 latent representation에 인코딩 한다.
그다음 class center와 cosine similarity를 계산한다.
마지막으로 threshold값을 통해 OOD를 수행한다.

이 결과에 따라 seen은 supervised classifier를 통해 처리하고
unseen은 f-CLSWGAN을 통해 처리한다.
Experiments
A. Experimental Settings

B. Out-of-Distribution Classification
본 방법에서는 threshold 값이 가장 중요한데,
선행연구에서 사용한 0.95값을 사용한다.

C. Comparison with State-of-the-Arts

D. Latent Space Visualization
파란색이 seen이다.

Conclusion
In this work, we present a novel gating GZSL method named SE-OOD. The proposed method learns a bounded manifold for each seen class by utilizing a semantic encoding network combined with a semantically consistent mapping. The key idea of our approach is to mitigate the underside impact of the seensimilar visual samples. By leveraging the learned manifolds, unseen samples can be easily separated from seen samples, and GZSL can be decomposed into a ZSL problem and a supervision learning task. The experimental results on four GZSL benchmarks show that the proposed approach outperforms the state-of-the-art methods by a large margin.


