Paper Overview
CVPR'20
https://arxiv.org/abs/2004.00666
Generalized Zero-Shot Learning Via Over-Complete Distribution
A well trained and generalized deep neural network (DNN) should be robust to both seen and unseen classes. However, the performance of most of the existing supervised DNN algorithms degrade for classes which are unseen in the training set. To learn a discr
arxiv.org
Abstract
Zero-Shot Learning (ZSL) 세팅에서 좋은 성능을 산출하는 classifier를 학습하기 위해,
저자들은 Over-Complete Distribution (OCD)를 만드는 것을 제안한다.
이것은 Conditional Variational Autoencoder (CVAE)를 사용하여 만든다.
class간의 분리성을 강화하고 class scatter를 줄이기 위해
저자들은 Online Batch Triplet Loss (OBTL), Center Loss (CL)를 사용한다.
Keywords
Zero-Shot Learning, Generalized Zero-Shot Learning, Classification, Over-Complete Distribution
Introduction
ZSL, GZSL을 다루기 위해 연구자들은 unseen distribution에 존재하는
sample을 합성하여 만드는방법을 제안한다.
그러나, 합성된 unseen class는 real unseen distribution을
따라하는 것에 실패한다. 특히 이것은 "hard sample"로 예측된다.
따라서, 합성으로 생성된 class는 성능에 크게 기여를 하지 못하게 된다.
이 성능 저하의 주된 이유 중 하나는 testing set이 "hard sample"을 포함하기 때문이다.
hard sample이란 다른 class와 가깝고 결정 경계가 test에서 최적화 되지 않는 경우를 말한다.
따라서 저자들의 주장은 다음과 같다.
hard sample을 생성하고 unseen class를 근사하는 것은 모델의 bias를 줄일 수 있다.
딸서 저자들은 Over-Complete Distribution (OCD) 개념을 제안한다.
OCD의 목적은 분리하기 어려운 sample을 만들어서
unseen에 대한 일반화 성능을 높이는 것이다.

위 그림과 같이 저자들은 Online Batch Triplet Loss (OBTL)로
class간의 분리성을 높이고 Center Loss (CL)로 class내에서 spread를 줄인다.
Proposed Framework

framework는 3가지 모듈로 구성된다.
(i) 한 encoder ($p_{E}(z|x)$)는 $x$가 주어지면 latent variable $z$를 계산한다.
(ii) 한 decoder ($p_{G}(\hat{x}|z,a)$)는 주어진 $z$와 attribute $a$를 통해 $\hat{x}$을 만든다.
(iii) 한 regressor ($p_{R}(\hat{a}|\hat{x})$)는 $\hat{x}$를 예측된 attribute $\hat{a}$에 매핑한다.
이 encoder, decoder를 결합한 모듈을 CVAE라 한다.
그리고 regressor는 OBTL와 CL 로 최적화 된다.
3.1 Over-Complete Distribution (OCD)
decoder의 주된 업무는 real unseen data에 비슷한 분포를 생성하고 근사하는 것이다.

위 그림과 같이 OCD를 만드는 것은 모든 가능한 hard smaple을 생성하는것을 수반한다.
real unseen distribution의 양상을 시뮬레이팅하는 것은 어려운 문제기 때문에,
저자들은 먼저 한 class에 대한 OCD를 만들고 생성된 OCD가 real unseen 분포의 양상을 시뮬레이팅 하는 것을 보여준다.
OCD는 유한한 수의 multiple Gaussian distribution을 mix함으로써 만들어진다.
(다른 class를 향해 평균을 이동한다.)
한 class의 variational inference로부터 근사화된 분포의 파라미터를 $\mu$, $\sigma$라고 나타내고
over-complete distirbution은 $\mu_{OC}$, $\sigma_{OC}$($\sigma_{OC} > \sigma$)를 통해 나타낸다.
$\hat{X}$와 $\hat{X}_{OC}$를 각각 근사화된 unseen distribution과 over-complete distribution이라 하면 다음과 같다.


$p_{G}(\cdot )$는 pipeline의 generator모듈이다.
$\mu_{HP}$, $\sigma_{HP}$는 하이퍼 파라미터다.
$\mu_{z|\hat{X}}$와 $\sigma_{z|\hat{X}}$는 $\hat{X}$를 latent space $z$로 인코딩할때 얻어지는 값이다.
$\sigma ' _{HP}$는 하이퍼파라미터고 $j$는 random sample index다.
$N(\cdot )$는 가우시안 분포 generator다.
식 1의 첫번째 파트에서, unseen class의 분포 $\hat{X}$는 $z \sim N(\mu_{HP}, \sigma_{HP})$ with $a$에서
random sampling함으로써 생성된다.
식 1의 두번째 파트에서 $\mu_{z|\hat{X}}$와 $\sigma_{z|\hat{X}}$는 encoder $p_{E}(\cdot )$을 사용하여 추정한다.
식 2의 첫번째 파트에서, $\hat{X}_{OC}$는 비슷하게 $z \sim N(\mu_{OC}, \sigma'_{HP})$에서
random sampling함으로써 생성된다.
$\mu_{OC}$는 현재와 다른 class의 평균으로 추정한다.
Visualization of the Distributions

(b)는 CVAE를 통해 예측되고 생성된 unseen distribution이다.
그러나 (a)에서, unseen real distribution은 다른 class와 비슷하게 붙어있고, 일부 겹쳐있다.
만약 생성된 분포가 real 분포의 양상을 따라하지 못한다면
각 분포는 학습에 한계가 있다.
보통, 각 distribution에 학습된 classifier는 unseen clasd에 잘못 수행된다.
(c)는 OCD가 적용된 nseen class의 근사된 분포를 나타낸다.
해당 분포를 통해 unseen class에 대한 성능을 개선할 수 있다.
3.2. Proposed OCD-CVAE Framework Training
3.2.1 Loss Functions
Online Batch Triplet Loss to Maximize Inter Class Distance
tirplet loss는 다음과 같다.

$f$는 embedded feature vector를 나타낸다.
$\alpha$는 margine을 나타낸다.
저자들은 Online Batch Triplet Loss를 제안한다.
배치 단위로 트리플렛을 생성하면 검색 공간을 줄여
하드 네거티브 샘플을 찾고 딥 모델의 총 교육 시간을 단축할 수 있다고 한다.
(대충 배치 슥 뽑고 거기서 pos, neg 정하겠다는 뜻)
Center Loss
regressor는 근사화된 $x$를 대응되는 attribute $a$에 매핑한다.
hard sample은 표준 편차가 크기 때문에,
over-complete distribution에 대해 center loss를 최소화 하는 것은 중요하다.

3.2.2 Learning Phase of the Proposed Model
training set은 'S' seen class를 포함하고
testing set은 'U' unseen class를 포함한다.
본 논문은 inductive setting이라 보면 된다.
training에는 seen만 있고 unseen에 대해서는 attribute만 가지고 있음.
First phase of training
CVAE가 $D_S$로 먼저 학습된다.
따라서 latent variable [$z_i$, $a_i$]는 generator에 제공되어 $\hat{x}$를 만든다.
학습된 CVAE는 $a$에 따라 data를 합성할 수 있다.

위 식의 첫번째 항은 conditional marginal likelihood고 두번째 항은 KL-divergence다.
Second phase of training
두번째로 regressor가 $D_S$를 사용하여 다름 loss로 학습된다.
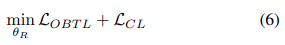
Third phase of training
세번째 단계에서 $D_s$와 OCD가 이용된다.
첫번째 phase로부터 generator parameter를 가져와서 학습에 사용한다.

따라서 다음과 같이 최종 loss를 학습한다.
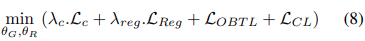
3.3 Implementation Details

Experiments
4.1. Database Details
SUN, CUB, AWA2를 사용한다.

4.2. Evaluation Protocol

4.3. Conventional Zero-Shot Learning (ZSL)

4.4. Ablative Study
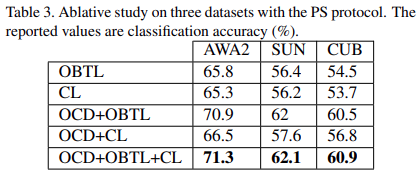
4.5. Generalized Zero-Shot Learning (GZSL)

4.6. Hyper-Parameter Selection

Conclusion
This paper addresses the challenge of Zero-Shot Learning and Generalized Zero-Shot Learning. We propose the concept of over-complete distribution and utilize it to train the discriminative classifier in ZSL and GZSL settings. An over-complete distribution is defined by generating all possible hard samples for a class which are closer to other competing classes. We have observed that over-complete distributions are helpful in ensuring separability between classes and improve the classification performance. Experiments on three benchmark databases with both ZSL and GZSL protocols show that the proposed approach yields improved performance. The concept of OCD along with optimizing inter-class and intra-class distances can also be utilized in other frameworks such as Generative Adversarial Networks, heterogeneous metric learning [11], and applications such as face recognition with disguise variations [30].


