이 논문은
Point clouds Inductive Generalized Zero shot semantic segmentatation
분야의 2번째 논문이다.
unseen feature 생성에 초점을 두었다.
3DGenZ 논문이 나온 후 2년만에 후속 연구가 발표된 것이라
아주 귀한 논문이라 할수 있다.
ICCV'23
ICCV 2023 Open Access Repository
Zero-Shot Point Cloud Segmentation by Semantic-Visual Aware Synthesis Yuwei Yang, Munawar Hayat, Zhao Jin, Hongyuan Zhu, Yinjie Lei; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11586-11596 Abstract This paper p
openaccess.thecvf.com
Abstract
이 논문은 3D point clouds zero-shot semantic segmentation에 대해
feature synthesis(합성) 접근법을 제안한다.
unseen object에 대해 class-level semantic information만 주어지므로
저자들은 visual, semantic space사이의
correspondence, alignment, consistency를 향상시키려 노력한다.
저자들은 masked learning strategy를 적용하여
같은 class visual feature 내에서 다양성을 촉진하고
다른 class 사이에서 차별성을 향상한다.
나아가 visual feature를 prototypical space에 던져서
모델의 분포를 대응되는 semantic space에 alignment한다.
마지막으로, consistency regularizer를 사용하여
real seen feature와 synthetic-unseen feature 사이의
semantic-visual 관계를 보존한다.

1. Introduction
저자들은 generalized zero-shot learning에서
inductive setting을 적용한다.
저자들은 다음 semantic-visual transfer issue를 고려한다.
1. Semantic-Visual Correspondence Mismatch
Semantic, Visual vector는 서로 다르기 때문에
mapping하는 함수를 학습하는게 ZSL의 핵심이다.
2. Heterogeneous Semantic-Visual Embeding
Heterogeneous는 사전뜻으로 '여러다른 종류로 이뤄진'이다.
semantic vector와 visual representation은
각기 다른 모델로 부터 얻는 것이기 때문에
두 모델의 이종(異種)성을 align 해야 한다.
3. Inconsistent Semantic-Visual Relationship
Visual space와 semantic space가
일관성을 만들어
unseen visual representation은 본적 없어도
unseen semantic space로 visual space가 잘 구축되도록 해야 한다.
3. Methodology
3.1. Problem Definition
Ojbect category를 $C$라 하고
seen, unseen을 $C^S$, $C^U$라고 한다.
$D$를 dataset이라 할 때 point clouds $P$,
대응되는 label $Y$, semantic embedding $T$로 구성된다.
저자들은 inductive Generalized ZSL setting을 따른다.
저자들은 generator를 $G(\cdot )$이라 하고
feature embedding network를 $\theta( \cdot)$,
semantor를 $f(\cdot)$라고 한다.
학습과정을 요약하면 다음과 같다.
1. seen data를 사요하여 $f_{seen}$를 붙여서 $\theta$학습
2. $\theta$를 frozen하고 semantic vector를 사용하여 $G$학습
3. 생성된 unseen feature와 seen feature를 사용하여 $f_{final}$학습

3.2. Mask Correspondence Learning
semantic embedding $t_{s}^{c}$와 random noise $z_{s}^{s}$가 주어지면
$G( \cdot )$은 $\hat{F}_{s}^{c}$를 합성하는데
이것은 real feature $F_{s}^{c} = \theta( p_{s}^{c})$의 분포를 따른다.
2D는 pre-trained backbone을 통해 generator를 만들기가 용이하지만
3D는 그렇지 않다.
딸서 저자들은 input semantic과 output visual space의
강한 correspondence를 구축하는 것을 제안한다.
$G$는 같은 클래스 내에서 diversity가 있어야 하고
다른 class간에 decision boundary가 명백해야 한다.
따라서 저자들은 masking strategy를 사용한다.
(참고로 이 masking 방식은 point clouds classification
Point-BERT논문에서 point를 masking한 뒤
디코딩하여 복구하는 방식이 backbone학습에 도움이 된다는 연구가 있다.)
위 그림을 보면 point cluds $p_{s}^{c}$에 대응되는
semantic embedding $t_{s}^{c}$을 랜덤으로
마스킹하고 $G$를 통해 feature를 생성한다.

⊕는 concatenation을 뜻하고
$H(q)$는 확률 $q$적으로 일부를 '0'을 곱하는 것이다.(마스킹)
이렇게 학습하면 intra-class diversity를 학습하는데 도움이 된다.
(아마 random noise와 더불어
마스킹의 랜덤성이 diversity를 늘려주는 것으로 보인다.)
추가로 다른 class간의 차이를 명확하게 하기 위해
저자들은 $\theta$로 추출한 real fature $F_{s}$ 중에서
같은 class에 속하는 것을 positive sample $F_{s}^{c}$로 하고
다른 seen class $k$로 추출한 것을 negative sample $F_{s}^{k}$라 한다.
이것을 InfoNCE loss로 학습한다.

3.3. Heterogeneous Prototype Alignment
저자들은 1.에서 언급한 2. 문제를 다루기 위해 feature 생성 전에
cross-modality heterogeneous feature를 align하는 것을 제안한다.
저자들은 protopyical learning에 영감을 받아
original feature를 prototypical space에 던져서
distribution을 alignment하도록 모델링한다.
저자들은 visual prototype가 필요하다. (semantic은 학습때 주어진다.)
visual prototype를 만들기 위해
단순하게 visual feature를 평균하는 것 대신에
저자들은 neighbor-aware approach를 사요하여
intra-class fine-grained local structure를 반영한다.
구체적으로, 저자들은 Farthest Point Sampling (FPS) 알고리즘을 통해
$r$-proportion (0 < $r$ < 1) point feature $\left\{F_{s}^{c,a}\right\}_{a=1}^{\lfloor n*r\rfloor}$을
real seen feature $\left\{F_{s}^{c,i}\right\}_{a=1}^{n}$의 anchor로 한다.
$\lfloor \cdot \rfloor$은 rounding operation이다.
저자들은 $n$ point feature간의 L2 거리와 $\lfloor n*r \rfloor$ anchor를 계산하고
nearest anchor index에 각 point를 할당한다.
저자들은 같은 anhor index의 point feature를 평균내어
$\lfloor n*r \rfloor$ visual prototype $\left\{H_{s}^{c,b}\right\}_{b=1}^{\lfloor n*r\rfloor}$을 얻는다.

$\xi_{s}^{c,b}$는 anchor $b$에 할당된 piont feature의
partition region이다.
이렇게 visual prototype를 얻고난 후 align을 하여 합성 퀄리티를 높인다.
저자들은 linear $\sigma ( \cdot )$을 통해 semantic embedding을
대응되는 visual prototype으로 매핑하고 cosine distance $d$를 줄인다.
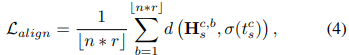
나아가 저자들은 이 $\sigma(t_{s}^{c}$를 합성된 feature $\hat{F}_{s}^{c}$에 더하여
visual representation을 향상시켜 $G$학습에 사용한다.
게다가 이것은 추후 unseen feature를 생성할 때도 도움이 된다.
3.4. Relational Transfer Consistency
모델은 절대로 unseen data를 학습에서 볼 수가 없다.
그래서 모델은 어쩔 수 없이 unseen도 seen class라고 편향되게 된다.
저자들은 CSRL approch에 영감을 받아
semantic-visual consistency regularizatoin을 제안한다.
저자들은 seen, unseen이 semantic, visual structure를 가지더라도
이것들 각각의 space에서 inter-class relationship도 보존되어야 한다 생각한다.
구체적으로, 저자들은 $G$가 unseen visual feature를 합성한게
semantic prototype와 대응되어야 한다는 것이다.
이건 seen도 마찬가지다.
따라서 저자들은 다음과 같이 seen, unseen visual synthetic prototype를 만든다.
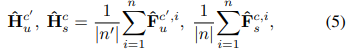
나아가 저자들은 semantic $W$, visual $V$의
distance distribution relation matrices를 얻는다.

이를 할용하여 두 space가 일관성 있도록 만든다.

3.5. Network Training and Inference
저자들은 우선 $\theta$와 $f_{seen}$을 통해
backbone을 학습한다.

$G$는 Maximum Mean Discrepancy (MMD) loss를 사용한다.

이를 활용하여 최종 $G$ loss는 다음과 같다.
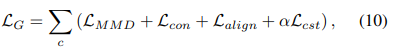
최종적인 classifier는 다음 loss로 학습한다.

4. Experiments
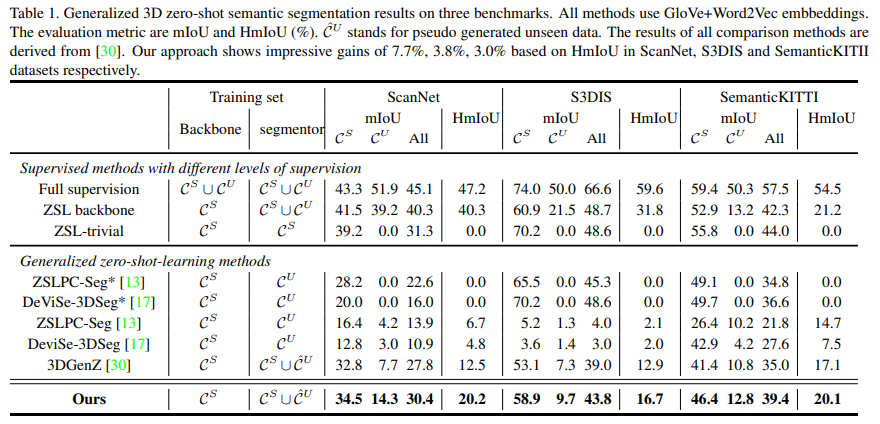
Dataset은 ScanNet, S3DIS, SemanticKITTI를 사용한다.
4.2. Experimental Results
Quantitative comparision with the state-of-art mthods
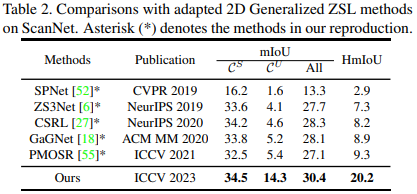
More comparisions with adapted 2D methods
Qualitative results

4.3. Ablation study
Ablation study of different modules

Dissecting MCL module

Prototypes in HPA and RTC module

Effects of different auxiliary semantic embeddings



