Paper Overview
ACM MM'23
https://arxiv.org/abs/2210.09923
Zero-shot point cloud segmentation by transferring geometric primitives
We investigate transductive zero-shot point cloud semantic segmentation, where the network is trained on seen objects and able to segment unseen objects. The 3D geometric elements are essential cues to imply a novel 3D object type. However, previous method
arxiv.org
Abstract
본 논문은 transductive zero-shot learning 논문이다.
3D geometric elements는 새로운 3D object 형태를 설명할 중요한 정보다.
그러나 선행연구들은 language와 3D geometic elements 사이의 fine-grained 관계를 고려하지 않았다.
따라서, 본 논문은 seen과 unseen 카테고리가 공유하는 geomentic primitives를 학습하고 이를 사용하는 novel framework를 제안한다.

구체적으로, 저자들은 novel point visual representation, 즉 point feature와 learnable prototype간의 similarity vector를 공식화 한다.
추가로 novel Unknown-aware InfoNCE loss를 제안하여 visual representation과 language를 align한다.
Keywords
Zero-Shot Point Cloud Segmenation, Transductive Zero-Shot Learning
Related Work
참조한 선행 연구
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Clouds [paper][blog]
Proposed Method
1. Problem Definition
저자들이 사용하는 학습 데이터셋은 다음과 같이 나타낼 수 있다.
$D_{train}^{trans}=\left\{(X_{i}^{s}, W_{i}^{s}, Y_{i}^{s})_{i=1}^{N^{s}}, (X_{j}^{u}, W_{j}^{u})_{j=1}^{N^{u}}\right\}$
즉, transductive setting은 unseen dataset에 대해서 label 없이 접근 가능한 환경이다.
최종 목표는 한 장면 내에서 모든 카테고리를 정확히 예측하는 것이다.
2. Approach Overview

저자들의 famework는 위와 같다.
먼저 seen과 unseen의 point-wise feature를 추출한 다음 visual representation부터 공식화 한다.
이 visual representation은 geometirc primitive와 point feature간의 similarity vector다.
그다음, Unknown-aware InfoNCE Loss를 통해 visual, semantic fine-grained alignment를 수행한다.
3. Visual Representation with Geometric Primitives
저자들의 기본 아이디어는 다음과 같이 3D object를 learnable geometic primitive로 구분하는 것이다.

이 geometic primitives는 새로운 3D object에 대해서도 유효할 것이다.
따라서 본 논문은 먼저 seen과 unseen 카테고리의 공유하는 3D geometric elements를 학습하고 이것을 새로운 object에 적용하는 것이다.
저자들은 W2V 논문과 같이 visual representation을 정의한다.
한 point는 dictionary가 될 수 있고, W2V의 "word frequency"는 point feature와 대응되는 geometric primitive간의 유사성이다.

이때 $g$는 geometric primitives고, $\alpha$는 $g$에 대응하는 weight다:

$d$는 dot product operation을 의미한다.
$\lambda$는 inversed temperature term을 의미한다.
$\theta$와 $\phi$는 각각 key와 query 함수로 신경망 레이어를 사용한다.
따라서 다음과 같이 point를 geometic weight vector로 나타낼 수 있다.

위 $\alpha$의 합은 1이다.
앞으로 모든 input point feature를 식(3)과 같이 나타내어 사용한다.
4. Fine-grained Alignment on Visual and Semantic Representation
이제 visual, semantic representation간의 fine-grained alignment를 수행한다.
Semantic Representation of Mixture Distribution
저자들은 word embedding을 generation network에 입력하여 word representation vector를 생성한다.

$w$는 word embedding을 나타낸다.
$G$는 generation network를 나타내는데 총 $K$개가 존재한다.
$G_{k}$로부터 생성된 vector의 합을 최종 word representation으로 사용한다.
그러나 위 식에서 정의된 $\tilde{w}$의 sum operation은 사용되지 않으니 대충 $\hat{w}$의 집합을 나타낸다 치고 넘어가면 된다.
Unknown-aware InfoNCE Loss
본 논문은 ground-truth를 사용하여 다음 loss를 통해 모델을 학습한다.

이때 $D$는 다음과 같이 정의된다.

식 (4)에서 정의한 word representation은 사용하지 않고 sum operation을 적용하기 전 $\hat{w}$를 사용하여 dot product를 진행하는 것을 볼 수 있다.
일반적으로 zero-shot 모델의 예측은 seen 카테고리에 편향된다.
특히, 비슷한 seen 카테고리에 편향이 될 것이다.
따라서 unlabed unseen data는 seen data에서 멀리 떨어지게 만든다.

이를 위해 다음과 같은 loss를 사용한다.
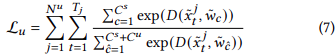
식 (5)와 식(6)을 합쳐서 학습 loss로 사용한다.

Inference
레이블 할당은 학습된 word represenation과 유사도를 계산하여 결정한다.

Experiments
1. Dataset
ScanNet, S3DIS, SemanticKITTI, NuScenes를 사용한다.
2. Evaluation Metircs
hIoU를 사용한다. (IoU 설명)

3. Implementation Details


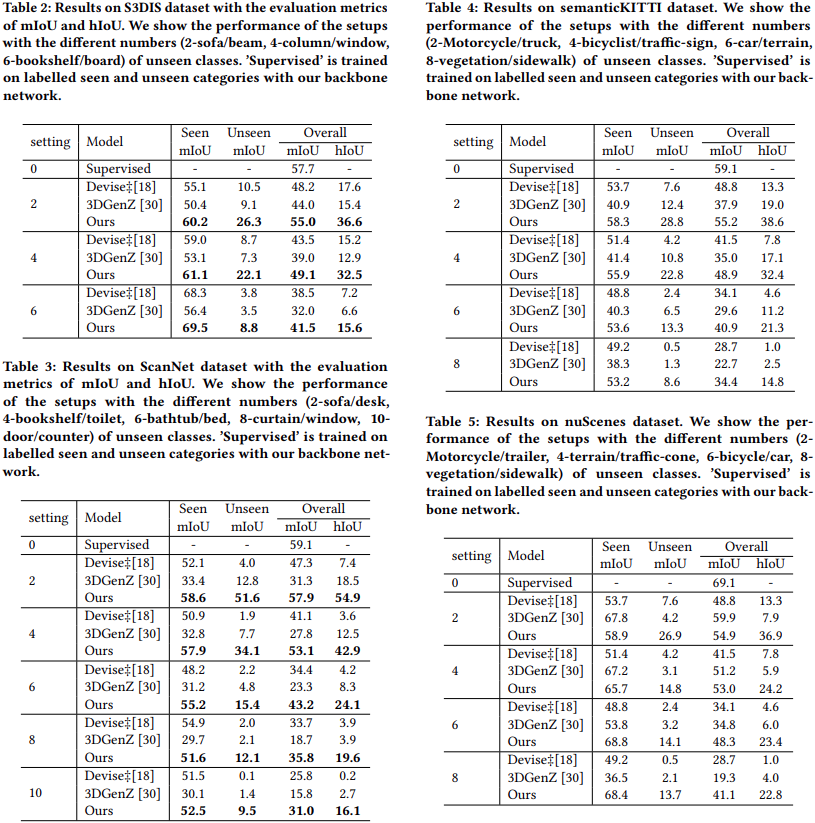
4. Results and Discussion


Performance under differnet number of unseen classes
3DGenZ는 unseen data를 사용하지 않는 inductive setting이라서,
unseen data를 사용하는 본 논문보다 성능이 떨어지는게 당연하다.
5. Ablation Study
Base는 $\mathcal{L}_{s}$만을 사용한 모델이다.
$\mathcal{L}_{pseudo}$는 seen data를 바탕으로 argmax로 unseen labeling을 하여 학습한 결과다.
$\mathcal{L}_{self}$는 Fixmatch라는 self-supvervised 방식을 사용한 결과다.
GP는 geometric primitive를 나타낸다.
MK는 multi-kernels semantic representation을 나타낸다.

Conclusion
We investigate transductive zero-shot semantic segmentation in this paper. Our method models the fine-grained relationship between language and geometric primitives that transfers knowledge from seen to unseen. To this end, we propose a novel visual feature representation and a novel Unknown-aware InfoNCE Loss. Therefore, under the guidance of semantic representation, the network can segment the novel objects represented by the learned geometric primitives. Extensive experiments conducted on four datasets show that our method significantly outperforms other state-of-the-art methods.


